- Published on
In-depth look at ACID properties of Postgres


ACID Properties in Postgres
In the world of database systems, ACID (Atomicity, Consistency, Isolation, Durability) is a set of properties that guarantee the reliability and correctness of data transactions. These properties are essential for any database that needs to maintain the integrity of data, especially in the case of multiple concurrent transactions. In this blog, we will delve into the ACID properties of Postgres and see how they work internally to ensure the reliability and consistency of data.
Atomicity
Atomicity is the property that ensures that a transaction is either completed in its entirety or not at all. This means that if a transaction fails for any reason, the database will roll back the changes made by the transaction, leaving the data in its previous state.
When a transaction is initiated in PostgreSQL, it is assigned a unique transaction ID (XID). The XID is used to identify the transaction throughout its lifecycle. When a statement is executed within a transaction, PostgreSQL writes the changes made by the statement to a transaction log (also known as the write-ahead log or WAL). The WAL contains a record of all changes made to the database by a transaction. This log is used to ensure that the transaction can be rolled back (undone) if it fails or is aborted.
The WAL works by writing a log record for every change made to the database, along with the XID of the transaction that made the change. The log record contains enough information to recreate the change, including the old and new values of any affected rows. If a transaction encounters an error or is aborted, PostgreSQL uses the information in the WAL to undo any changes made by the transaction. In case of database restart, the WAL log is used to recover the database to its previous state. Lastly, it's important to note that database will not accept new transactions until it has recovered to a consistent state.
Let's demonstrate this with some code.
-- Note: Every statement is a transaction (i.e. it is atomic)
CREATE TABLE users (
id SERIAL PRIMARY KEY,
name VARCHAR(255) NOT NULL,
age INT NOT NULL
);
SELECT * FROM users; -- Before inserting data
INSERT INTO users (name, age) VALUES ('John Doe', 22);
SELECT * FROM users; -- After inserting data
BEGIN; -- Start a transaction (or use `BEGIN TRANSACTION`)
UPDATE users SET name = 'Tony Stark' WHERE age = 22;
-- Next statement will fail because of missing value so the the database will ignore the whole tranasaction
INSERT INTO users (name) VALUES ('Foo Bar');
-- Now postgres will ignore all the statements (even if correct) after the failed statement (except COMMIT/ROLLBACK)
INSERT INTO users (name, age) VALUES ('Bar Baz', 33);
COMMIT; -- End the transaction. Note that postgres will reply with "ROLLBACK" because the transaction failed
SELECT * FROM users; -- After a failed transaction we can see that nothing has changed
-- Bonus: You can use `SAVEPOINT` to create a savepoint in a transaction
-- This allows you to roll back to a specific point in the transaction
Consistency
Consistency is the property that ensures that a transaction leaves the database in a valid state. This means that the transaction must follow all rules and constraints defined on the data, such as foreign key constraints, unique indexes, and check constraints.
In Postgres, consistency is maintained through the use of constraints and triggers. Constraints are rules that are defined on the data and are enforced by the database. Triggers are functions that are executed by the database when certain events occur, such as the upserting data to a table. Both constraints and triggers can be used to ensure that the data remains consistent and follows all rules and constraints defined on it.
CREATE TABLE users (
id SERIAL PRIMARY KEY,
name VARCHAR(255) NOT NULL,
age INT NOT NULL
);
CREATE TABLE comments (
id SERIAL PRIMARY KEY,
user_id INT NOT NULL,
comment TEXT NOT NULL,
created_at TIMESTAMP NOT NULL DEFAULT NOW(),
updated_at TIMESTAMP NOT NULL DEFAULT NOW()
);
-- Foreign key constraint to ensure data consistency
ALTER TABLE comments ADD FOREIGN KEY (user_id) REFERENCES users(id);
-- Unique constraint to ensure that each user has a unique name
ALTER TABLE users ADD CONSTRAINT unique_name UNIQUE (name);
-- Check constraint to ensure that the age is at least 18
ALTER TABLE users ADD CONSTRAINT check_age CHECK (age >= 18);
-- You can also use a trigger to check the age of the user
CREATE TRIGGER check_age
AFTER INSERT OR UPDATE ON users
FOR EACH ROW
WHEN (NEW.age < 18)
BEGIN
RAISE EXCEPTION 'Age must be at least 18';
END;
-- Create a function + trigger to update the updated_at column of the comments table
CREAATE OR REPLACE FUNCTION update_updated_at()
RETURNS TRIGGER AS $$
BEGIN
NEW.updated_at = NOW();
RETURN NEW;
END;
CREATE TRIGGER update_updated_at
BEFORE UPDATE ON comments
FOR EACH ROW
EXECUTE PROCEDURE update_updated_at();
-- Now let's try to upsert some data that violates the constraints
INSERT INTO users (name, age) VALUES ('John Doe', 17); -- This will fail because of the check constraint
UPDATE users SET age = 17 WHERE id = 1; -- This will fail because of the trigger/exception
INSERT INTO comments (user_id, comment) VALUES (1, 'Hello World'); -- This will fail because of the foreign key constraint
-- Create a user with a valid age, create a comment, and update the comment
INSERT INTO users (name, age) VALUES ('John Doe', 22);
INSERT INTO comments (user_id, comment) VALUES (1, 'Hello World');
SELECT * FROM comments;
-- Now update the comment and see the updated_at column change
UPDATE comments SET comment = 'Hello World!' WHERE id = 1;
SELECT * FROM comments;
-- Bonus tip: Try using trigger to call pg_notify when a row is modified
-- You can then use LISTEN to listen for notifications and build real-time applications!
Side note: Differences between primary key and UNIQUE constraints:
- Both primary key and unique constraints automatically create an index on the specified columns, which can improve the performance of queries that involve those columns. However, a primary key constraint creates a clustered index, which determines the physical order of the data in the table, while a unique constraint creates a non-clustered index.
- A table can have only one primary key, and it cannot contain null values.
- A table can have multiple unique constraints, and they can contain null values.
Isolation
Isolation is the property that ensures that the changes made by a transaction are not visible to other transactions until the transaction is committed (or wants to do so based on isolation level). This is important because it prevents other transactions from reading data that may be in an inconsistent state.
In Postgres, isolation is achieved through the use of MVCC (Multi-Version Concurrency Control). MVCC works by maintaining multiple versions of each row in the database, with each version representing a snapshot of the data at a particular point in time. When a transaction starts, it reads the current version of the data and makes its changes to a new version. These changes are not visible to other transactions until the transaction is committed, at which point the new version becomes the current version.
It's important to understand that here MVCC snapshots aren't huge backups. Postgres does it very efficiently. It maintains xmin and xmax column values for each row. xmin represents the transaction id of the transaction that created the row, and xmax represents the transaction id of the transaction that deleted the row. If xmax is not null, it means that the row has been deleted and is no longer visible to other transactions. If xmax is null, it means that the row is visible to other transactions.
You can use SELECT *, xmin, xmax FROM table to take a look at the xmin and xmax values for the currently visible rows in a table (for your transaction). I'm yet to figure out how to see past versions of all rows at the same time. Reach out to to me if you figured out how to do this :)
| column1 | column2 | column3 | ... | columnN | xmin | xmax |
-------------------------------------------------------------
| value1 | value2 | value3 | ... | valueN | 100 | 200 |
| value4 | value5 | value6 | ... | valueN | 50 | 300 |
| value7 | value8 | value9 | ... | valueN | 200 | 400 |
| ... | ... | ... | ... | ... | ... | ... |
Btw, if you're wondering that so many 'useless' rows due to MVCC will bloat the database, don't worry. Postgres has a process called vacuuming that cleans up the old versions of the rows. It's a bit complicated so I'll leave it for another blog post :)
Now we know how isolated transactions are initialized and how they work. But, if you have written any concurrent program, you'd be expecting some edge cases that need to be handled. Databases are no different - they face faces 3 edge cases (read phenomena) when implementing isolation:
- Dirty reads: This occurs when a transaction reads data that has been modified but not yet committed by another transaction. This can lead to inconsistent data if the transaction that made the changes is rolled back or aborted.
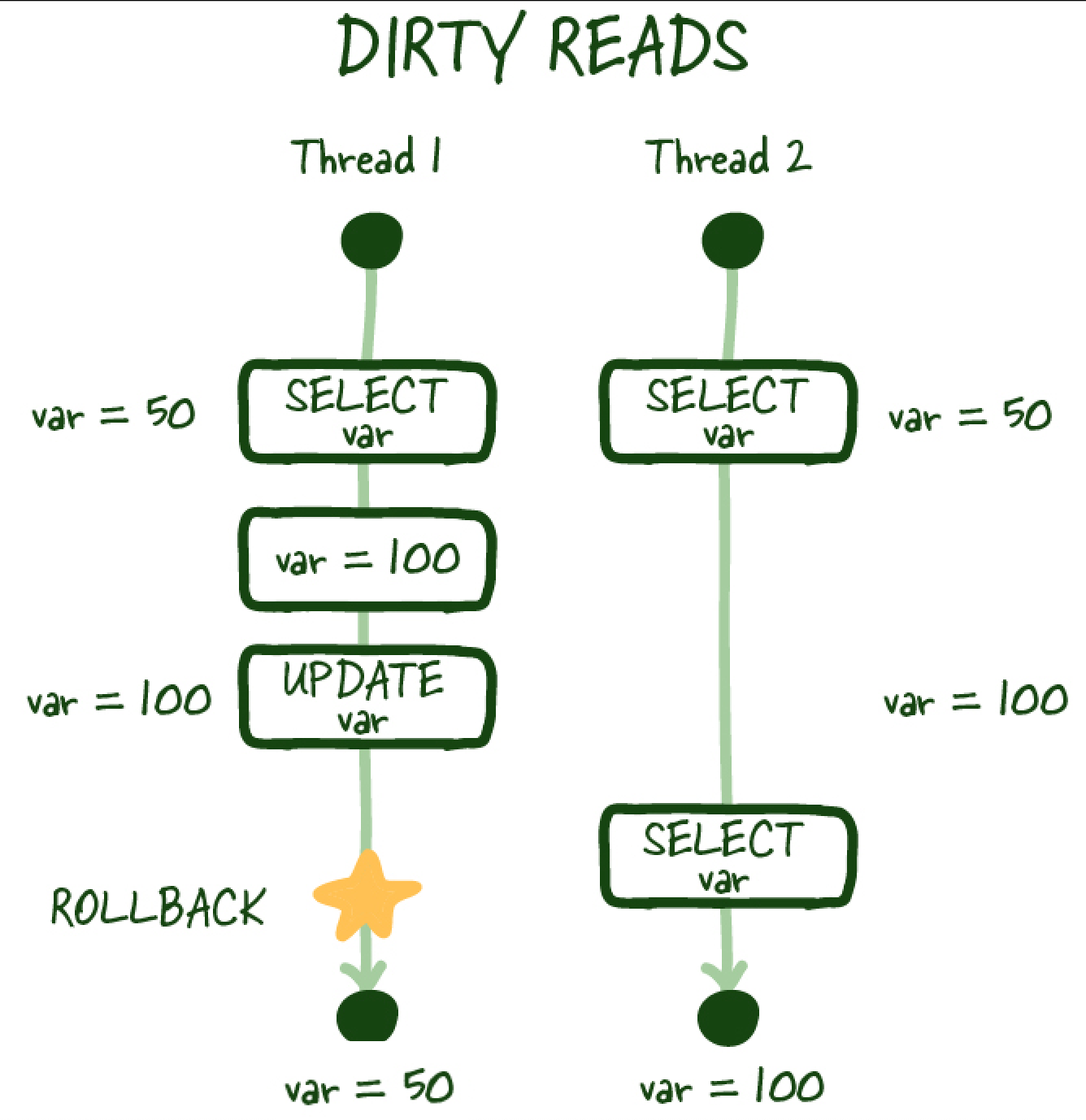
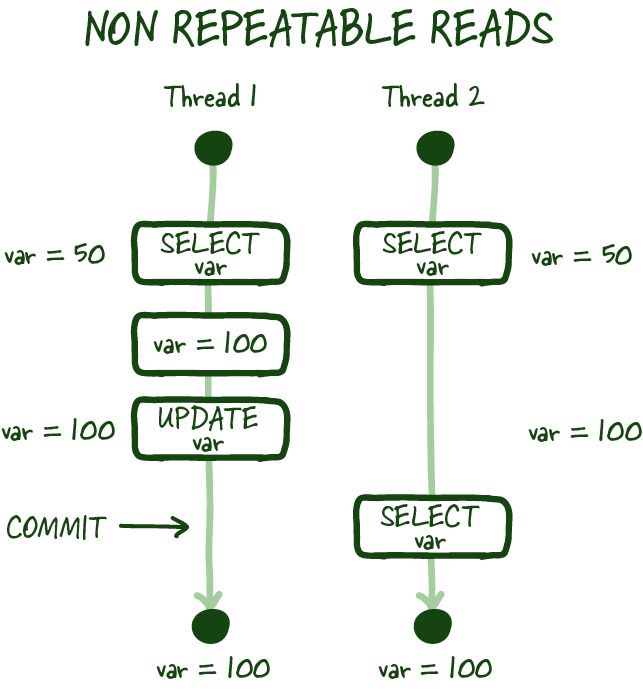
- Non-repeatable reads: This occurs when a transaction reads the same data multiple times and the data changes in-between those reads. This can lead to inconsistent data if the transaction that made the changes is rolled back or aborted.
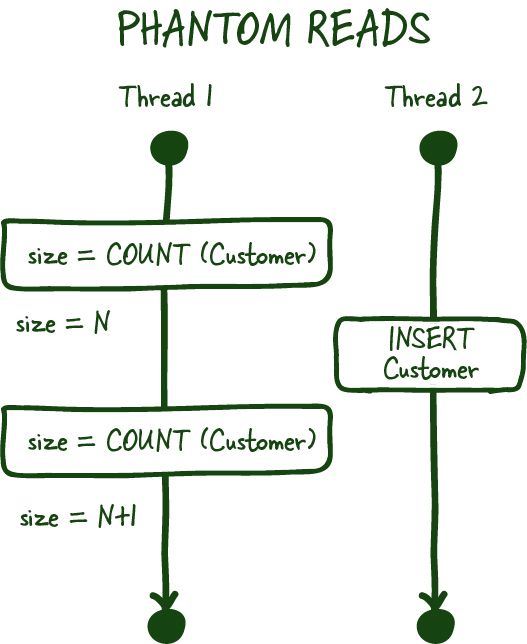
- Phantom reads: This occurs when a transaction reads a set of rows that satisfy a certain condition, and meanwhile another transaction inserts or deletes rows that would also satisfy that condition. This can lead to inconsistent data if the transaction that made the changes is rolled back or aborted.
Here's a table to summarize the different isolation levels and the read phenomena handled by at each level in Postgres.
| Isolation Level | Dirty Reads | Non-repeatable Reads | Phantom Reads |
|---|---|---|---|
| Read uncommitted | No | No | No |
| Read committed | Yes | No | No |
| Repeatable read | Yes | Yes | Yes |
| Serializable | Yes | Yes | Yes |
Read committed is the default isolation level in Postgres.
Note: Most databases aren't able to prevent phantom reads at the repeatable read isolation level. Postgres is one of the few databases that can do this because of its MVCC implementation. (because it essentially creates a snapshot of the data at the start of the transaction)
Let's dive into an example to see how isolation works in postgres:
-- Create a table first
CREATE TABLE users (
id SERIAL PRIMARY KEY,
name VARCHAR(255) NOT NULL,
age INT NOT NULL
);
-- Insert some dummy data
INSERT INTO users (name, age) VALUES ('John Doe', 22), ('Jane Doe', 21);
-- start a transaction (T1) and read the data
-- T1:
BEGIN TRANSACTION ISOLATION LEVEL READ COMMITTED; -- This is the default isolation level so you may just use `BEGIN;`
SELECT * FROM users;
-- Open a different terminal and start a second transaction (T2)
-- T2:
BEGIN;
UPDATE users SET name = 'New John Doe' WHERE id = 1;
SELECT * FROM users; -- Changes are visible to T2
-- Read the data again in the first transaction (T1)
-- T1:
SELECT * FROM users; -- Note that changes are not visible to T1 (yet)
-- Essentially, the second transaction's updates are not visible until the
-- first transaction is committed. So now we commit T2
-- T2:
COMMIT;
-- Now run this in T1 and you'll see that the changes are visible
-- T1:
SELECT * FROM users;
There are always trade-offs. So choose according to your needs:
- If you need to ensure that your transactions are isolated from each other and that the data they read is consistent, you should use a higher isolation level such as repeatable reads or serializable.
- If you need to maximize concurrency (and hence performance) and are willing to trade off some isolation, you can use a lower isolation level such as read committed. Higher isolation levels means a txn might have to wait for other txns.
Durability
Durability is the property that ensures that the changes made by a transaction are permanent and will not be lost in the event of a system failure.
Postgres keeps a lot of data in memory and regularly flushes it to the disk. This is done to improve performance and reduce the number of disk reads and writes since they are very very costly. However, this can lead to data loss in the event of a system failure. That's why, in postgres, durability is achieved through the use of write-ahead logging (WAL). WAL works by writing the changes made by a transaction to a log file before the changes are applied to the data. This log file is then used to recover the data in the event of a system failure.
Postgres takes durability one step further by using fsync to write the WAL directly to the disk and bypass the operating system's cache which could otherwise have tricked the database into thinking that the changes were written to disk when they were not. This ensures that the changes made by a transaction are persisted to disk and are not lost in the event of a system failure.
Here's how you can see the contents of the WAL files:
cd $PGDATA/pg_wal # $PGDATA is generally /var/lib/postgresql/data
ls -l
# You'll find a bunch of files that look like this: 000000010000000000000001
# Each one of these files represents different segments of the WAL
# Select one of the files and run the following command to see the contents of the file:
pg_waldump 000000010000000000000001 >> before.log
# You may run some queries to see the changes made by the queries in the WAL
CREATE TABLE users (
id SERIAL PRIMARY KEY,
name VARCHAR(255) NOT NULL,
age INT NOT NULL
);
INSERT INTO users (name, age) VALUES ('John Doe', 22), ('Jane Doe', 21);
# Now run the following command to see the contents of the WAL after the queries:
pg_waldump 000000010000000000000001 >> after.log
# Now get a diff:
diff before.log after.log
Conclusion:
In conclusion, the ACID properties of Postgres are essential for ensuring the reliability and consistency of data transactions. Atomicity ensures that transactions are completed in their entirety or not at all, consistency ensures that the data follows all rules and constraints, isolation ensures that the changes made by a transaction are not visible to other transactions unless required, and durability ensures that the changes made by a transaction are permanent and will not be lost in the event of a system failure. Together, these properties provide the foundation for building robust and reliable database systems that power all kinds of applications!
Credits:
- Architecture Notes for the isolatation level images
- Hussein Nasser and Arpit Bhayani for inspiring me to dive deeper into databases! Check out their channels on YouTube.